Prompt Engineering 101: Talk to AI Better
The highest-leverage AI skill you can learn in 30 minutes. Proven techniques from few-shot to chain-of-thought.
- Core prompting techniques: few-shot, chain-of-thought, role-play
- How to debug and iterate on prompts systematically
- When to use structured output vs. free-form
- Advanced patterns: self-consistency, tree-of-thought
1. What a prompt is really doing
Prompt Engineering 101: Talk to AI Better
The highest-leverage AI skill you can learn in 30 minutes. Proven techniques from few-shot to chain-of-thought.
Prompt anatomy
A strong prompt usually includes:
- Task: what to do
- Context: what the model should know
- Constraints: what to avoid or include
- Output format: how the answer should look
Why this matters
Large language models are sensitive to instruction detail. In practice, prompt quality often matters more than prompt length. A 20-word prompt with the right constraints can outperform a 200-word vague request.
Good vs weak prompt
Weak: "Write about climate change."
Stronger: "Write a 120-word explanation of climate change for a 14-year-old. Use one concrete example, avoid jargon, and end with one action people can take."
Key principle
Be explicit about the shape of the answer. The model cannot guess your preferred structure reliably if you leave it open."},{
2. Few-shot prompting and role-play
Few-shot prompting
Few-shot prompting gives the model a small set of input-output examples before the real query.
Use it when:
- The output format must be consistent
- The task is ambiguous
- You want the model to imitate a style or label scheme
Role-play prompting
Role-play sets a perspective or expertise level.
Examples:
- "You are a senior editor"
- "You are a patient math tutor"
- "You are a compliance analyst"
Role-play works best when paired with concrete instructions. A role alone is too vague.
Why examples work
Examples reduce ambiguity. They show the boundary cases. In machine learning terms, you are giving the model a tiny in-context training set."},{
prompt = """
You are a customer support classifier.
Label each message as Positive, Negative, or Neutral.
Examples:
Message: Thanks, that fixed it.
Label: Positive
Message: This still does not work.
Label: Negative
Message: I have a question about billing.
Label: Neutral
Now label:
Message: The update helped a lot, but login is still slow.
Label:
"""
print(prompt)Practical rule
Use three to five examples when consistency matters. Keep the examples short, clean, and representative. If the model starts copying the examples too literally, simplify the pattern or add a counterexample.
3. Reasoning prompts, chain-of-thought, and self-consistency
Chain-of-thought prompting
Chain-of-thought prompting asks the model to reason through intermediate steps before answering.
Best for:
- Multi-step math
- Logic problems
- Planning tasks
- Debugging code
Self-consistency
Self-consistency samples multiple reasoning paths and selects the most common answer.
Reference: Xuezhi Wang et al., 2022, Self-Consistency Improves Chain of Thought Reasoning in Language Models.
Tree-of-thought
Tree-of-thought search explores several branches instead of one linear path.
Use it when:
- There are many plausible next steps
- You need exploration, not just completion
- The task has a clear evaluation criterion
Tradeoff
More reasoning usually means more latency and cost. For simple tasks, direct answers are faster and often just as good."},{
When to ask for reasoning
Ask for step-by-step work when the task is hard enough that one hidden leap is likely to fail. For simple extraction, summarization, or rewriting, direct prompting is usually better.
4. Debugging prompts systematically
Prompt debugging checklist
- Identify the failure
- Remove unnecessary instructions
- Test with a small set of real inputs
- Add constraints one at a time
- Compare outputs against the goal
Structured output vs free-form
Use structured output when you need:
- Reliable parsing
- Database ingestion
- API calls
- Consistent fields
Use free-form when you need:
- Brainstorming
- Explaining
- Teaching
- Creative writing
Common failure modes
- The model ignores a constraint because it is buried too late
- The prompt asks for too many tasks at once
- The examples conflict with the instructions
- The format is underspecified"},{
{
"name": "Mina",
"role": "data analyst",
"task": "Summarize the chart in two sentences",
"output_format": "JSON with fields summary and risk"
}5. Advanced patterns and a practical workflow
Advanced prompt patterns
Self-consistency
Use multiple sampled reasoning paths and choose the most common answer.
Tree-of-thought
Explore several branches, score them, and keep the best path.
Structured output
Use schemas, tables, or JSON when another system depends on the result.
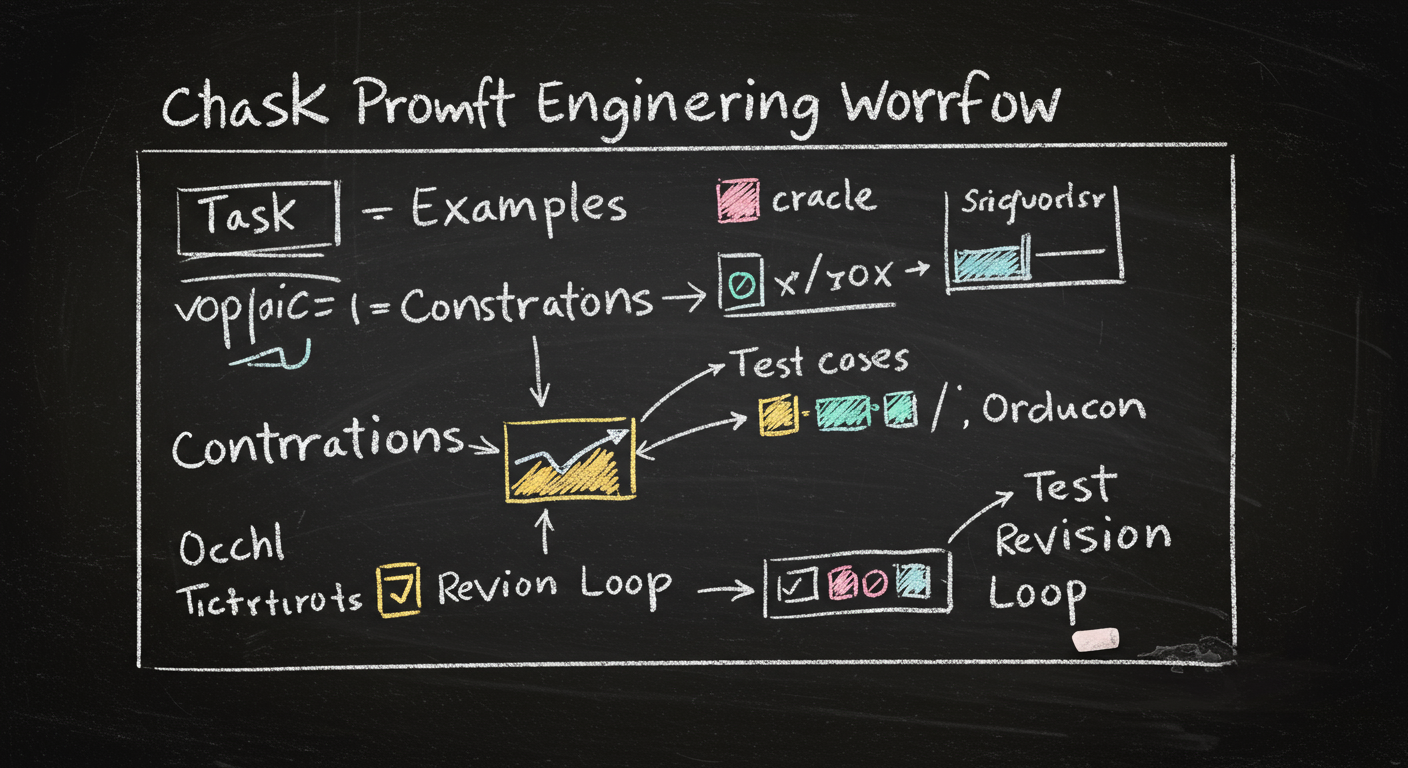
Practical workflow
- Write the task in one sentence
- Choose free-form or structured output
- Add examples if the task is ambiguous
- Test on real cases
- Revise one variable at a time
Decision rule
Human reader: free-form
Software reader: structured
Hard reasoning: step-by-step plus sampling
Exploration: tree-of-thought
Keep going with Slate
Pick up where this left off in your own voice session.