How ChatGPT Actually Works: LLMs Explained
Demystify transformers, training, fine-tuning, and hallucinations — how large language models really think.
- The transformer architecture in plain language
- How pre-training and fine-tuning shape model behavior
- What "emergent abilities" actually means
- Limitations: hallucination, reasoning gaps, context windows
1. What a large language model is
How ChatGPT Actually Works: LLMs Explained
Demystify transformers, training, fine-tuning, and hallucinations — how large language models really think.
Large language model basics
A large language model predicts the next token from the tokens before it.
A token is a chunk of text. For English, one token is often about 3 to 4 characters on average, though it varies a lot. The word “unbelievable” may split into multiple tokens. That matters because the model does not see text the way humans do.
What the model actually stores
The model stores parameters, often billions of them. GPT-3, released by OpenAI in 2020, had 175 billion parameters. Those parameters are learned weights inside a neural network. They are not a fact table.
Why next-token prediction is powerful
If a model gets very good at predicting the next token across huge amounts of text, it must learn patterns in:
- syntax
- semantics
- style
- common facts
- code structure
- question answering patterns
Analogy
Think of it like a musician who has heard millions of songs. They are not reciting a database of melodies. They have internalized patterns so deeply that they can improvise in many styles.
2. The transformer and attention
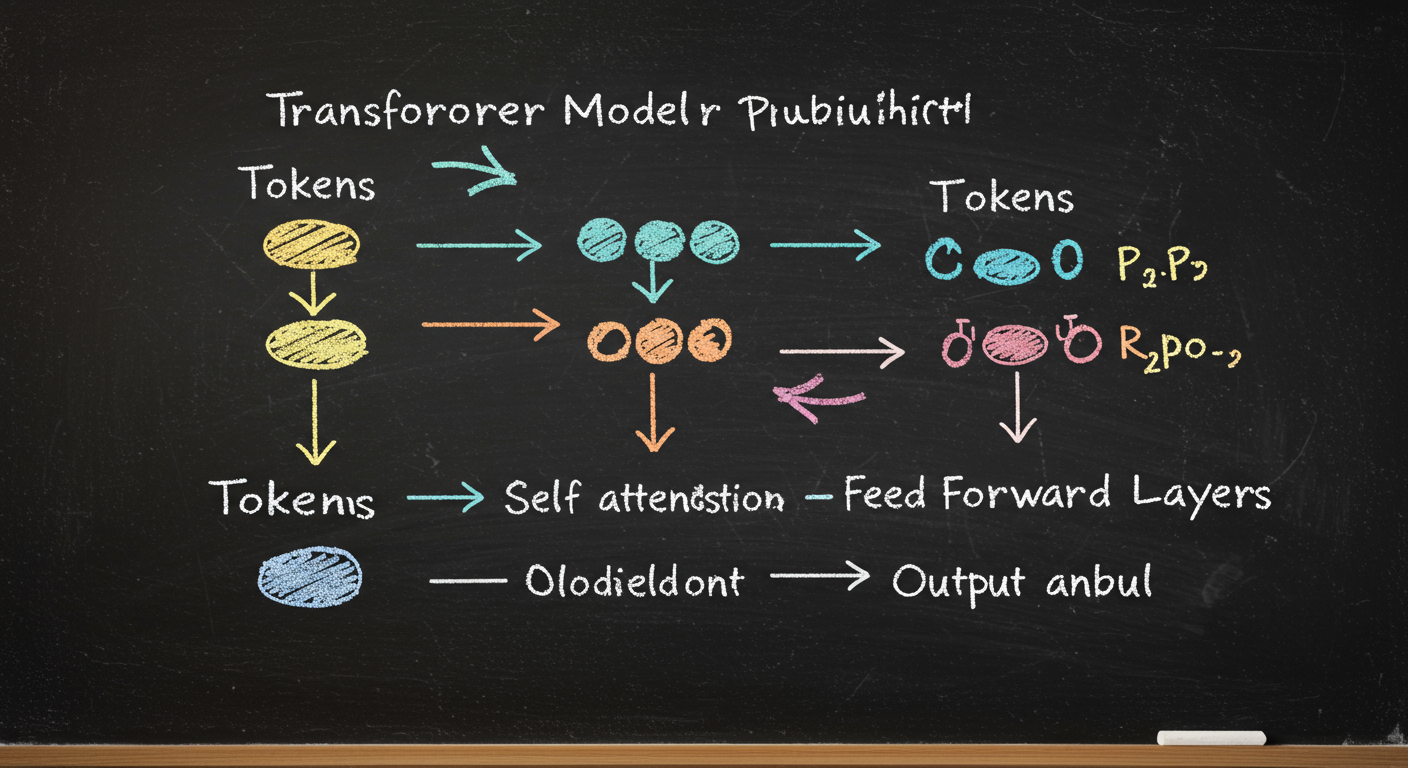
Transformer architecture in plain language
A transformer is a neural network built to process tokens in parallel and use attention to decide which tokens matter most.
The core pieces
- Token embeddings: turn tokens into vectors
- Positional information: tells the model token order
- Self-attention: lets each token look at other tokens
- Feed-forward layers: transform the attended information
- Many stacked layers: build higher-level patterns
Why attention matters
Attention gives the model a way to connect distant parts of text. That is much better than relying only on nearby words.
Analogy
Imagine a meeting where every person can glance at every other person’s notes before speaking. Self-attention is that shared glance. It helps the model decide which earlier words deserve focus right now.
3. Pre-training and fine-tuning
Pre-training vs fine-tuning
Pre-training teaches broad language and world patterns.
Fine-tuning teaches behavior: how to answer, what tone to use, and which tasks to prioritize.
Common fine-tuning methods
- Supervised fine-tuning: train on example prompts and ideal answers
- Instruction tuning: train on many instruction-following examples
- Reinforcement learning from human feedback: optimize toward human preferences
Real example
OpenAI’s InstructGPT paper, published in 2022, showed that models aligned with human feedback were preferred over the base model, even when they were smaller.
Analogy
Pre-training is like studying the whole library. Fine-tuning is like taking a specialized seminar on how to answer questions in the style your teacher wants.
import math
# Tiny next-token example with made-up probabilities
probs = {"Paris": 0.72, "London": 0.12, "Berlin": 0.08, "Rome": 0.08}
# Choose the most likely token
prediction = max(probs, key=probs.get)
print(prediction)
# Entropy shows uncertainty; lower means more confident
entropy = -sum(p * math.log2(p) for p in probs.values())
print(round(entropy, 3))4. Emergent abilities and context windows
Emergent abilities
Emergent abilities are behaviors that appear suddenly in evaluation even when underlying scale changes gradually.
That does not mean the model has consciousness or hidden intent. It means the measurement crossed a threshold.
Context window
The context window is the maximum amount of text the model can use at one time.
If the needed fact is outside the window, the model cannot directly consult it.
Why this matters
Long documents, large codebases, and multi-turn chats can exceed the context window. Then the model may forget early details or contradict itself.
Analogy
A context window is like the size of the whiteboard in front of a student. A bigger whiteboard lets them keep more of the problem visible at once.
5. Hallucinations, reasoning gaps, and safe use
Hallucination
A hallucination is a generated statement that is fluent but false, ungrounded, or misleading.
Why hallucinations happen
The model is trained to predict likely text, not to inspect reality directly.
Common failure modes
- Invented citations
- Confident but wrong factual claims
- Broken multi-step reasoning
- Forgetting earlier details beyond the context window
Best practice
Use the model for drafting, brainstorming, and pattern recognition. Verify important claims with trusted sources, execution, or calculation.
Analogy
A language model is like a brilliant improv actor. It can stay in character and keep the scene moving, but it may invent details that were never in the script.
Practical checklist for using ChatGPT well
- Ask for the reasoning or assumptions when the answer matters
- Verify names, dates, numbers, and citations
- Use retrieval or search for fresh facts
- Test code instead of trusting it blindly
- Keep the context focused when accuracy matters
Bottom line
ChatGPT is not a database and not a person. It is a transformer trained on next-token prediction, then tuned to follow instructions. Its strength is fluent pattern generation. Its weakness is that fluency can outrun truth.
Keep going with Slate
Pick up where this left off in your own voice session.